
Web-Scraping in Python: Beautiful Soup
Essentials of getting data directly from the web using the Beautiful Soup package
Why Web-Scrape
Web-Scraping can help with the efficiency of any project. Getting data directly from the internet saves time by eliminating the steps of downloading data, uploading it to a program, and then having to check if the data has changed. Overall, web-scraping helps regression models, machine learning, data visualization, and other data science related topics become more effective and efficient.
Web-Scraping Warnings
Web scraping is very helpful in efficiently getting data, but there are some things to look out for. Some websites do not allow web-scraping and doing so can cause issues. Although it oftentimes is still possible to get data from websites that discourage it, respecting companies and websites takes priority over analyzing data.
How to Web-Scrape in Python
For this example, I will be using a wikipedia table displaying general information about each season of the bachelor. That being said, this same process can be used to scrape tables and other information from other websites.
- To simplify web-scarping, the BeautifulSoup and urllib libraries will be used will be used (this reduces lines of code). If requests has already been installed, installation can be skipped.
pip install bs4 OR pip3 install bs4
pip install Requests OR pip3 install Requests
After installation, these libraries need to be imported into the Python file.
from bs4 import BeautifulSoup
from urllib.request import urlopen
- To access the website from Python, we will first copy the URL and save it as a varible.
url = "https://en.wikipedia.org/wiki/The_Bachelor_(American_TV_series)"
- Next, the urlopen() function will allow the code being written to access the website with the table wanted and save it to a variable. Following this, a variable called html will be created which will take the contents of the URL and decode them.
page = urlopen(url)
html = page.read().decode("utf-8")
Note: I am not going into much detail about utf-8, but it is basically an encoding standard which will allow the HTML contents to be useful in Python.
- With the html variable just created, we will now use BeautifulSoup to navigate through the site. What BeautifulSoup is doing here is searching through the jumble of text that was read into the html variable, and it finds elements.
soup = BeautifulSoup(html, "html.parser")
**Optional: To see how much text BeautifulSoup searches through, run the code below. Even the code below is a simplified version of the true text
print(soup.prettify())
- Now that the website information is in the code and parsed, the next step is to find the information for the desired table/information.
The first step to doing this is to inspect the html. In Google Chrome, navigate to the three dots in the top right corner, move to “more tools”, then select “developer tools.”
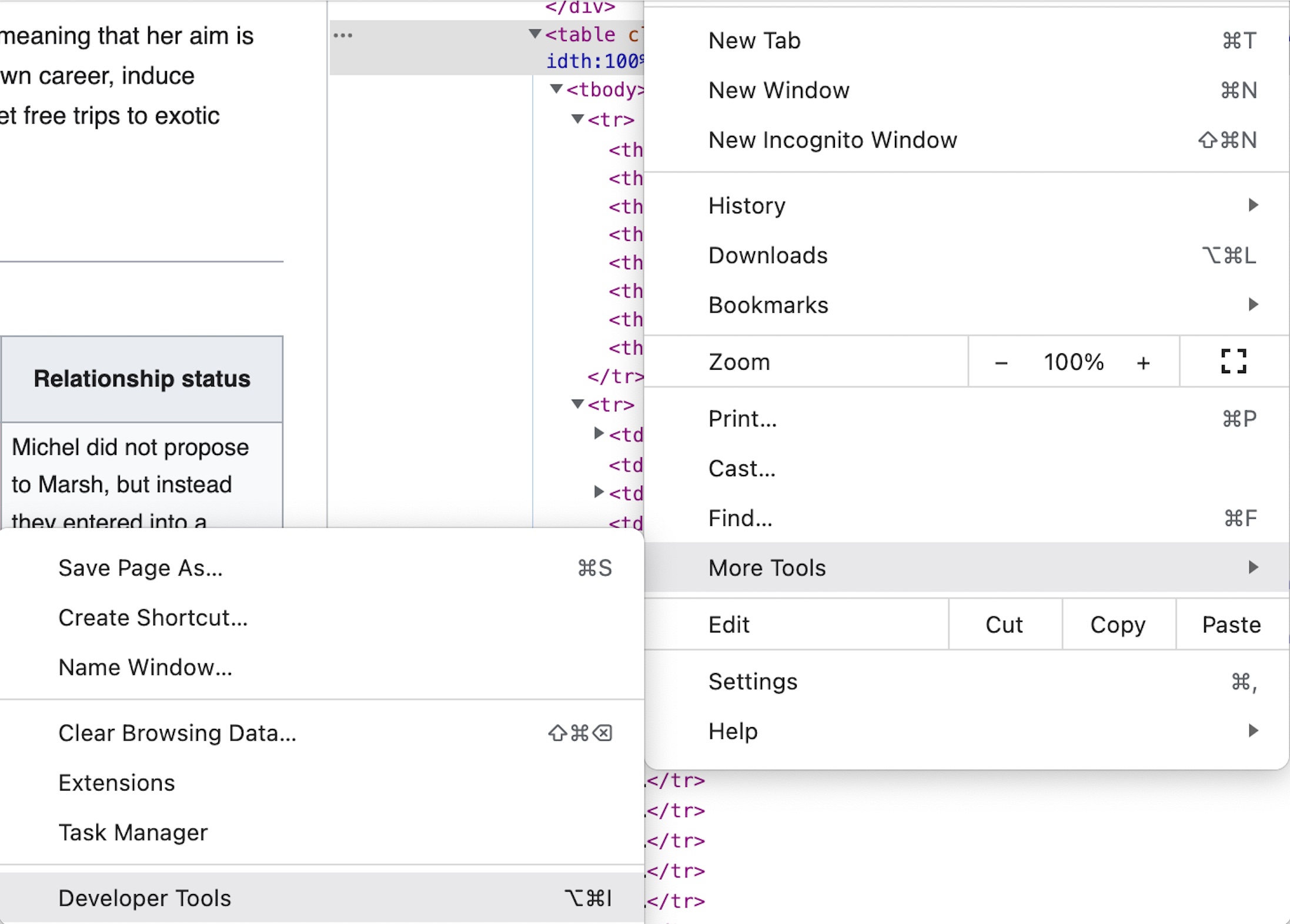
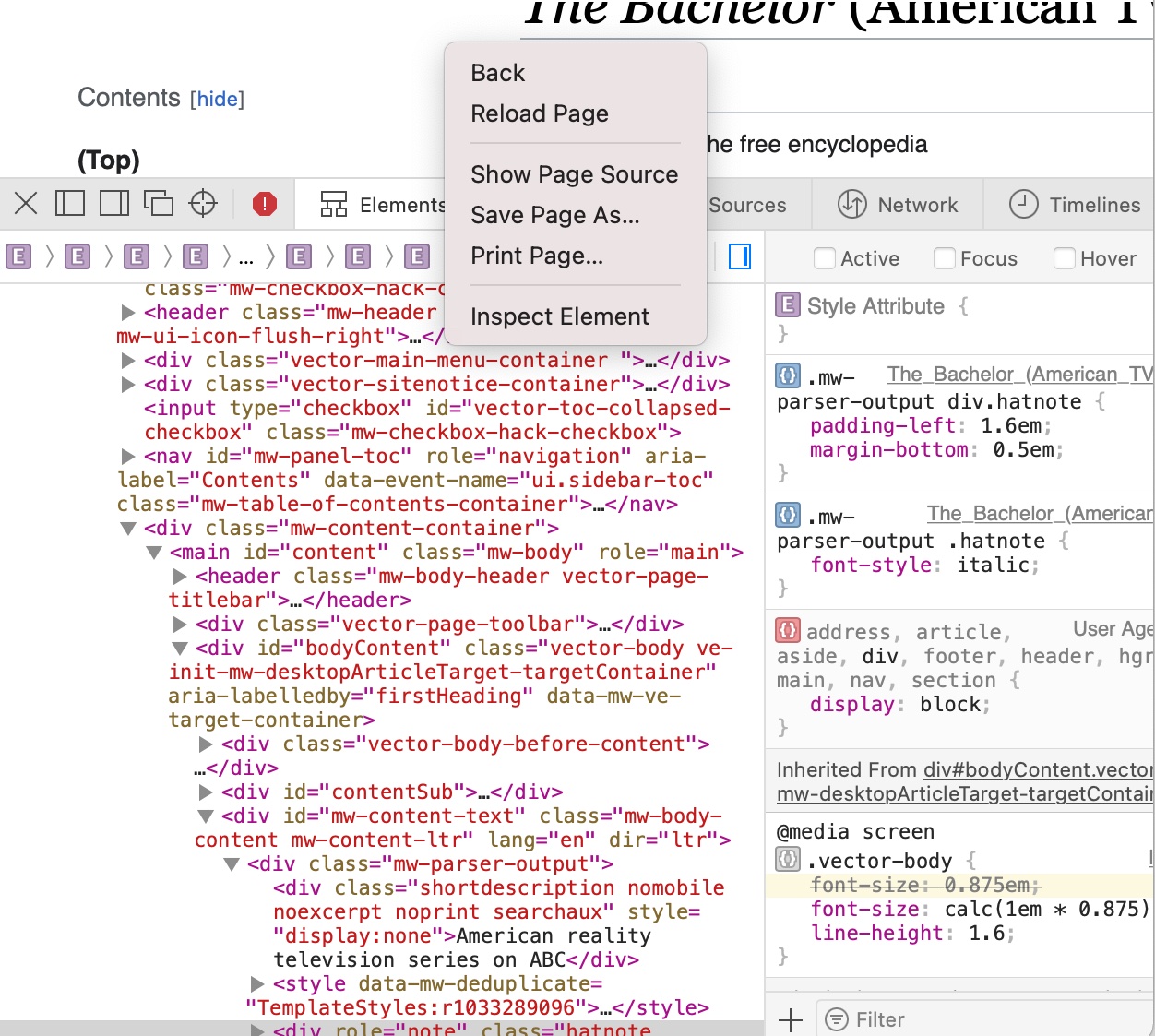
In Safari, right click on the window, and select “inspect elements.” If this option does not appear, try changing Safari preferences on the machine.
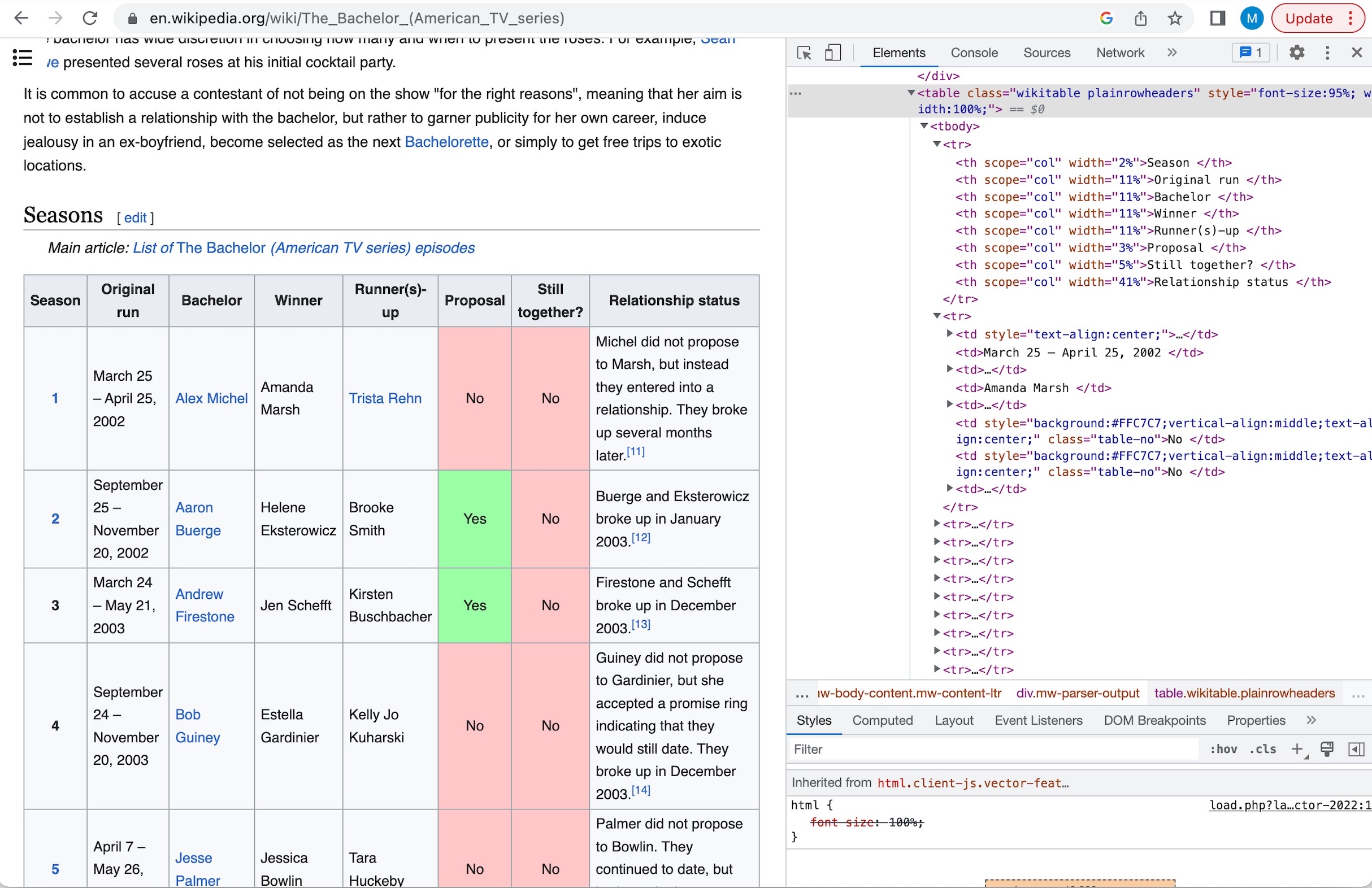
For this example, we want to find the “table” element. Navigating through the elements show that the desired table has a class aspect of “wikitable plainrowheaders.” The code below takes that table element from the soup variable and takes the table body elements from within that. The screenshot below visually shows how the ‘tbody’ element is included in the table element that has been selected.
s = soup.find("table", class_='wikitable plainrowheaders')
content = s.find_all('tbody')
- Next, create a dataframe that contains the column names in the table.
df = pd.DataFrame(columns=['Season', 'Original run', 'Bachelor', 'Winner', 'Runner(s) up', 'Proposal', 'Still together?', 'Relationship status'])
- As seen in the table, each row is a different element. To get all of this data into one table, we will use a for loop that calls the common column and row names. This will add the desired data into the recently created dataframe.
for row in table.tbody.find_all(‘tr’): columns = row.find_all(‘td’)
if(columns != []):
season = columns[0].text.strip()
original_run = columns[1].text.strip()
bachelor = columns[2].text.strip()
winner = columns[3].text.strip()
runner_up = columns[4].text.strip()
proposal = columns[5].text.strip()
together = columns[6].text.strip()
relationship_status = columns[7].text.strip()
df = df.append({'Season': season, 'Original run': original_run, 'Bachelor': bachelor, 'Winner': winner, 'Runner(s) up': runner_up, 'Proposal': proposal, 'Still together?': together, 'Relationship status': relationship_status}, ignore_index=True)
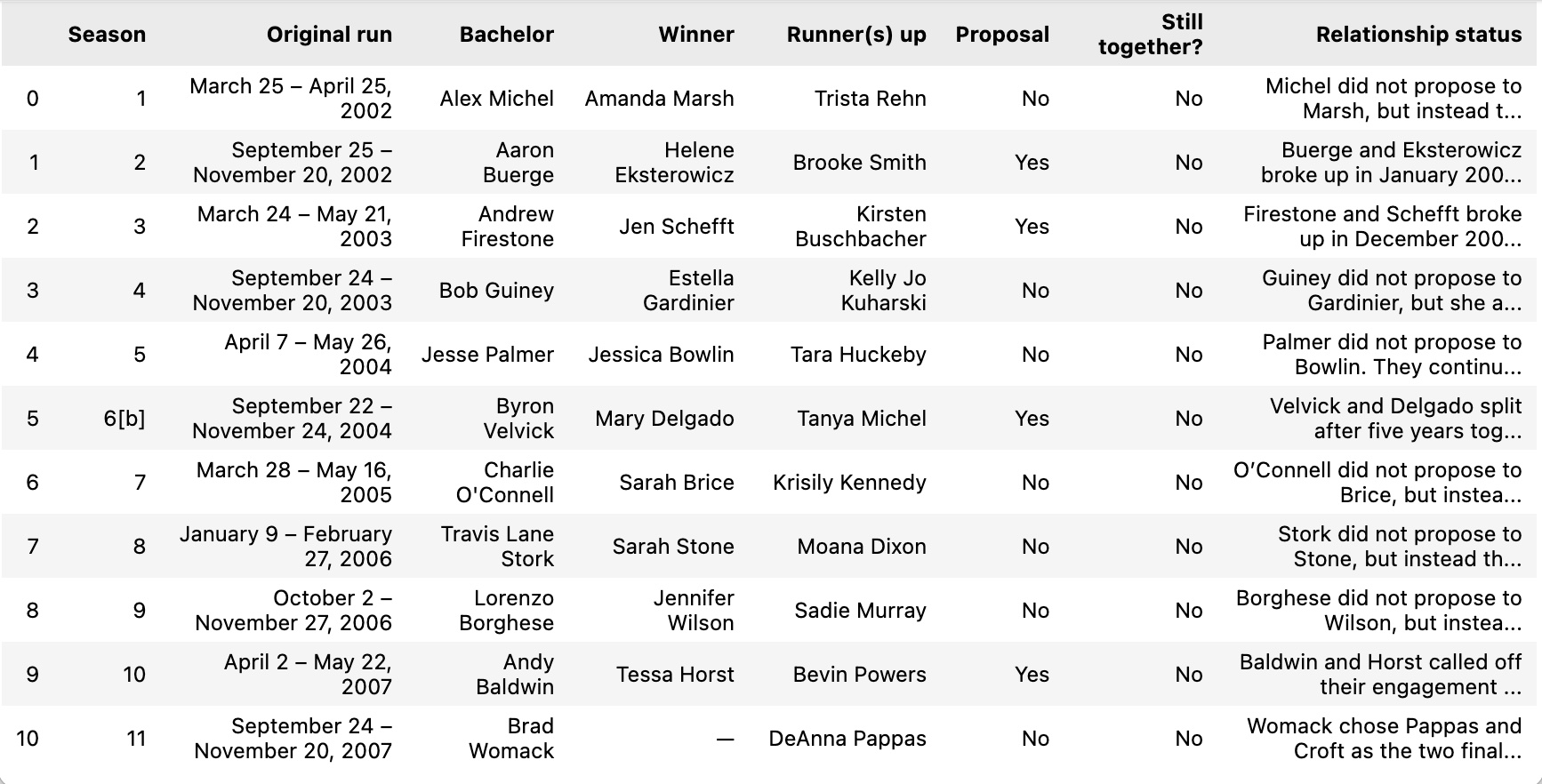
- Lastly, we will call on the dataframe to ensure proper importing. For this example, the table should look like the one below.
df
Final Notes
There are other ways to web-scrape in Python, but this is a template that can be changed based on what type of information is needed. Web-scraping is a very valuable skill, and can create more efficient data science processes.